Configure load balancing in the Requesty Console.
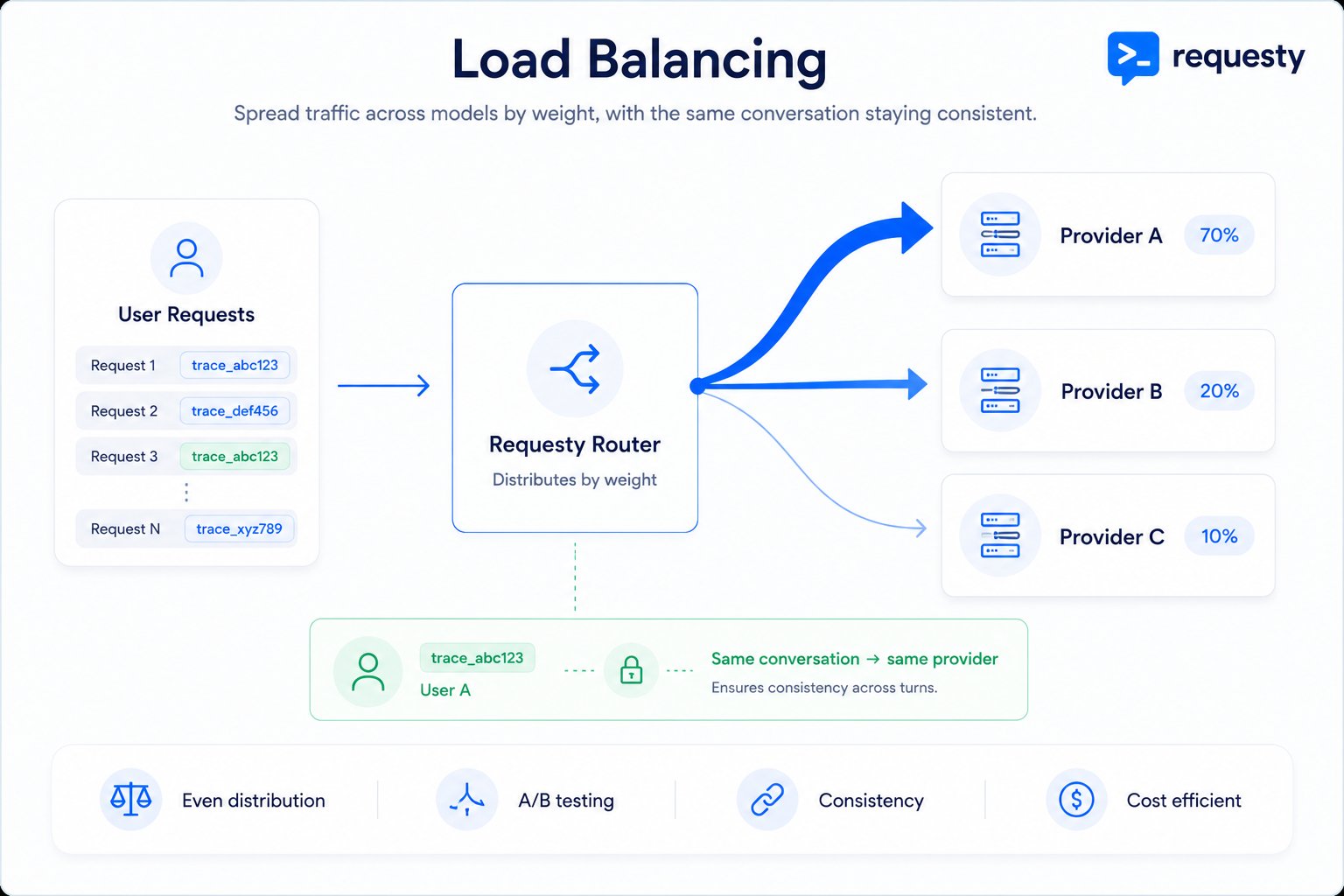
How It Works
Requests are routed
Each incoming request is consistently routed to one model based on the distribution.
Benefits
A/B Testing
Compare model performance with real traffic split across different models.
Gradual Rollouts
Send 10% to a new model, 90% to your stable model. Increase gradually.
Cost Optimization
Route most traffic to cheaper models while keeping premium models available.
Consistent Experiences
Same user always gets the same model, maintaining conversation context.
Creating a Load Balancing Policy
Create the Policy
Go to Routing Policies, click Create Policy, and select Load Balancing as the policy type.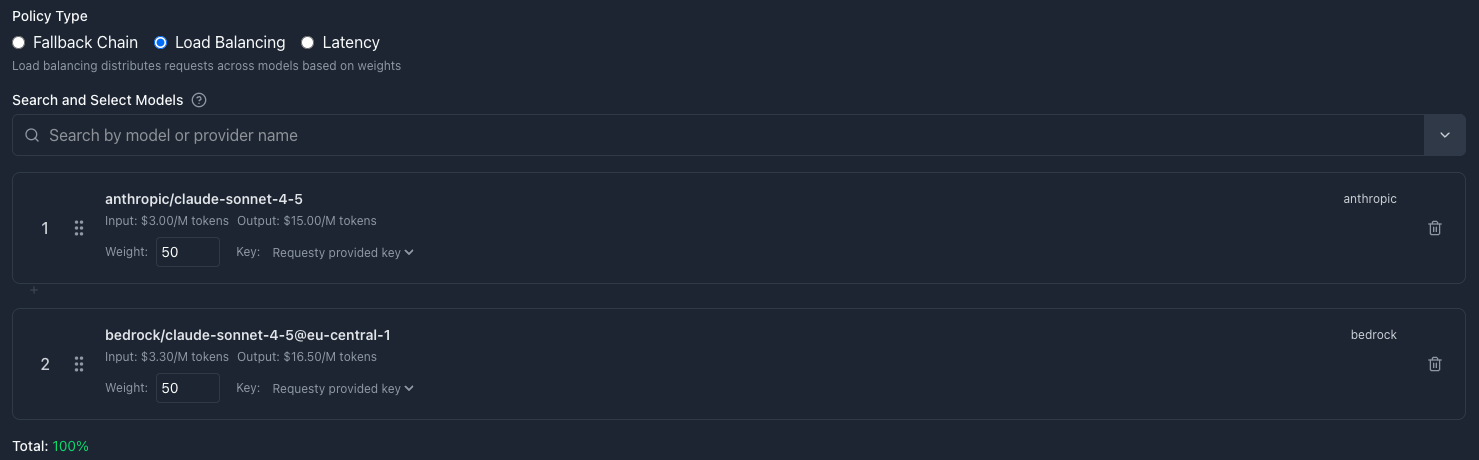
Configure Weights
Set up your distribution. For example:
The total weights must add up to 100% (you can use any numbers, they are normalized).
| Model | Weight |
|---|---|
anthropic/claude-sonnet-4-5 | 50% |
bedrock/claude-sonnet-4-5@eu-central-1 | 50% |
Consistency Guarantee
Load balancing uses deterministic hashing to ensure the same user always gets the same model.| Scenario | Behavior |
|---|---|
With trace_id | All requests with the same trace_id route to the same model |
Without trace_id | Requesty generates a unique request_id for each request |
Maintaining Consistency Across Requests
To keep a user on the same model across multiple requests, pass atrace_id:
Load Balancing Between Policies
You can load balance between entire routing policies, not just individual models. This is powerful for canary deployments, A/B testing different routing strategies, and gradual migration from one policy to another.Example: Policy Rollout
Say you have two fallback policies and want to gradually shift traffic:| Policy | Models | Weight |
|---|---|---|
policy/production-fallback (stable) | openai/gpt-5.2 → anthropic/claude-sonnet-4-5 | 80% |
policy/experimental-fallback (new) | google/gemini-2.5-pro → openai/gpt-5.2 | 20% |
gradual-rollout with these weights. As you gain confidence, adjust to 50/50, then 0/100.
Use Cases
A/B Testing New Models
A/B Testing New Models
Compare GPT-5.2 vs Gemini 2.5 Pro on real traffic:
Track performance in Analytics and see which model performs better.
| Model | Weight |
|---|---|
openai/gpt-5.2 | 50% |
google/gemini-2.5-pro | 50% |
Gradual Model Rollout
Gradual Model Rollout
Carefully introduce a new model:
Increase the weight of
| Model | Weight | Role |
|---|---|---|
openai/gpt-4o | 90% | Stable, proven |
openai/gpt-5.2 | 10% | New, testing |
gpt-5.2 as you validate quality.Cost-Optimized Distribution
Cost-Optimized Distribution
Route most traffic to cheaper models, some to premium:
| Model | Weight |
|---|---|
openai/gpt-4o-mini | 70% |
openai/gpt-4o | 20% |
openai/gpt-5.2 | 10% |
Multi-Provider Redundancy
Multi-Provider Redundancy
Distribute across providers for resilience:
| Model | Weight |
|---|---|
openai/gpt-5.2 | 40% |
anthropic/claude-sonnet-4-5 | 40% |
google/gemini-2.5-pro | 20% |
Key Selection (BYOK)
For each model in your load balancing policy, you can choose:| Option | Description |
|---|---|
| Requesty provided key | Use Requesty’s managed keys (default) |
| My own key | Use your BYOK credentials |
Monitoring and Analytics
Open Analytics
Go to Analytics.
Filter by policy
Filter by your policy name to see the actual distribution of requests across models.
FAQ
How does consistent hashing work?
How does consistent hashing work?
Requesty uses the xxhash algorithm on your
trace_id (or request_id if no trace_id) to deterministically select a model. The same ID always produces the same hash, which maps to the same model.What happens if I change the weights?
What happens if I change the weights?
Changing weights will re-distribute traffic. Some users may switch to different models. If you need stability, avoid changing weights frequently, or use separate policies for stable vs experimental traffic.
Can I load balance and have fallback?
Can I load balance and have fallback?
Yes. Create a load balancing policy that points to fallback policies. This gives you both load balancing and automatic failover.
| Policy | Weight |
|---|---|
policy/openai-fallback | 50% |
policy/anthropic-fallback | 50% |
Do all models need to be compatible?
Do all models need to be compatible?
Yes. All models in a load balancing policy should support the same request format and features. Do not mix chat models with embedding models, or models with different context lengths.
How do I ensure exactly 20% of users see the new model?
How do I ensure exactly 20% of users see the new model?
Use a stable
trace_id (like user ID). With 100+ unique users, the distribution will converge to your configured weights (e.g., 20%). With small sample sizes, expect ±5% variance.